“在隔离期间的不在状态的生活节奏,必然导致我工作效率的低下。究极原因是自己没有好好地反思自己做毕设的pipeline应该是如何的。我在很早的时候就画出了做毕设的思维导图,而且一直按着表走,效果也不赖,但是到了扩展数据集这一步,我失策了。”
隔离很淦
我在隔离期间,碰到的一个颇具规模的任务就是给12837张标注了hand的数据集修改标签,将hand分为left hand和right hand,也就是将标签分类。当然整个任务不止这一步,由于我没有成熟的分类模型,分类不会很准确,后续操作还有校正分类,调整标注框。
12837张图片per person真的是一个很令人头皮发麻而且催眠的任务,长时间的屏幕时间也会给眼睛造成疲劳反应,然后任务就得停停。在酒店隔离的生活有两个主旋律:倒时差和点餐。不同于转机,直飞国内带来的是快速换时区,我在飞机上都来不及睡觉就进入多达6小时的防疫时间,进入酒店睡过第一个晚上以为自己倒过来了,实际上是透光的窗帘让一天的生活提前醒来,而这样的窗帘会在接下来的14天维持我的时差。时差难倒,但是每天的点餐时间也不能错过,于是被闹钟催促着赶着的吃饭的节奏,也在14天里让我对吃饭印象最深。
话说回来,在隔离期间的不在状态的生活节奏,必然导致我工作效率的低下。究极原因是自己没有好好地反思自己做毕设的pipeline应该是如何的。我在很早的时候就画出了做毕设的思维导图,而且一直按着表走,效果也不赖,但是到了扩展数据集这一步,我失策了。
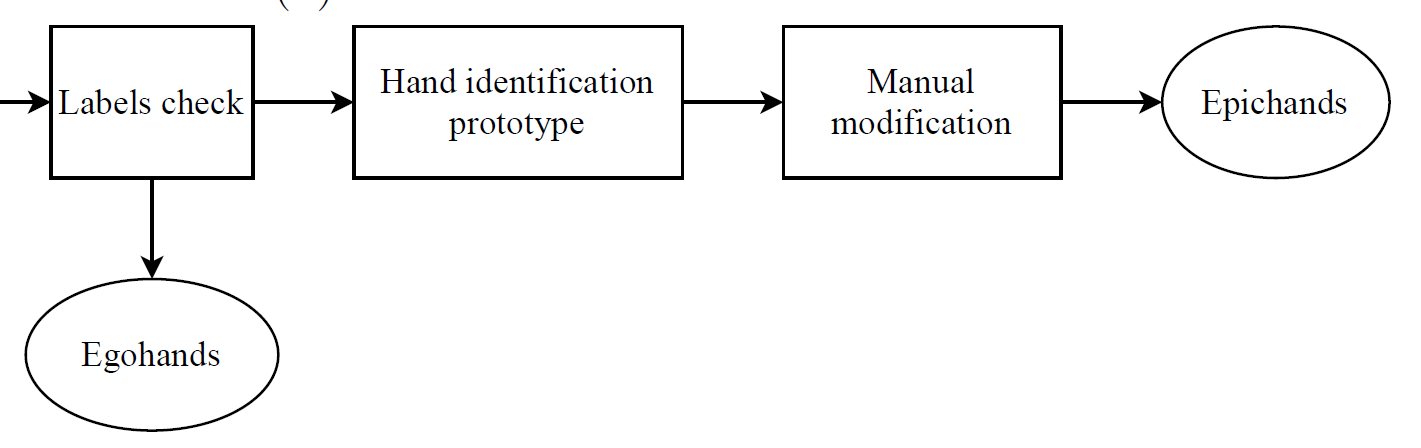 ◎ 来自我的初稿初版
◎ 来自我的初稿初版我的计划图展示了我修改数据集经历的主要两步:1)使用分类模型prototype对所有真实标注进行分类;2)在Supervisely上手动校正和修改。第一步,首先我采用了我stage-2算法中的(b)算法,也就是基于分割与基于倾斜角的经验模型的分类器,然后投入第二步漫漫校正路。
结果是我修改前面一半(6000+)图片花了四天。
我测过速,我心无旁骛的时候,50张图片能在1分10秒内处理完,假如说加入分心时间,一共2min处理50张图片,那么6000张应该在
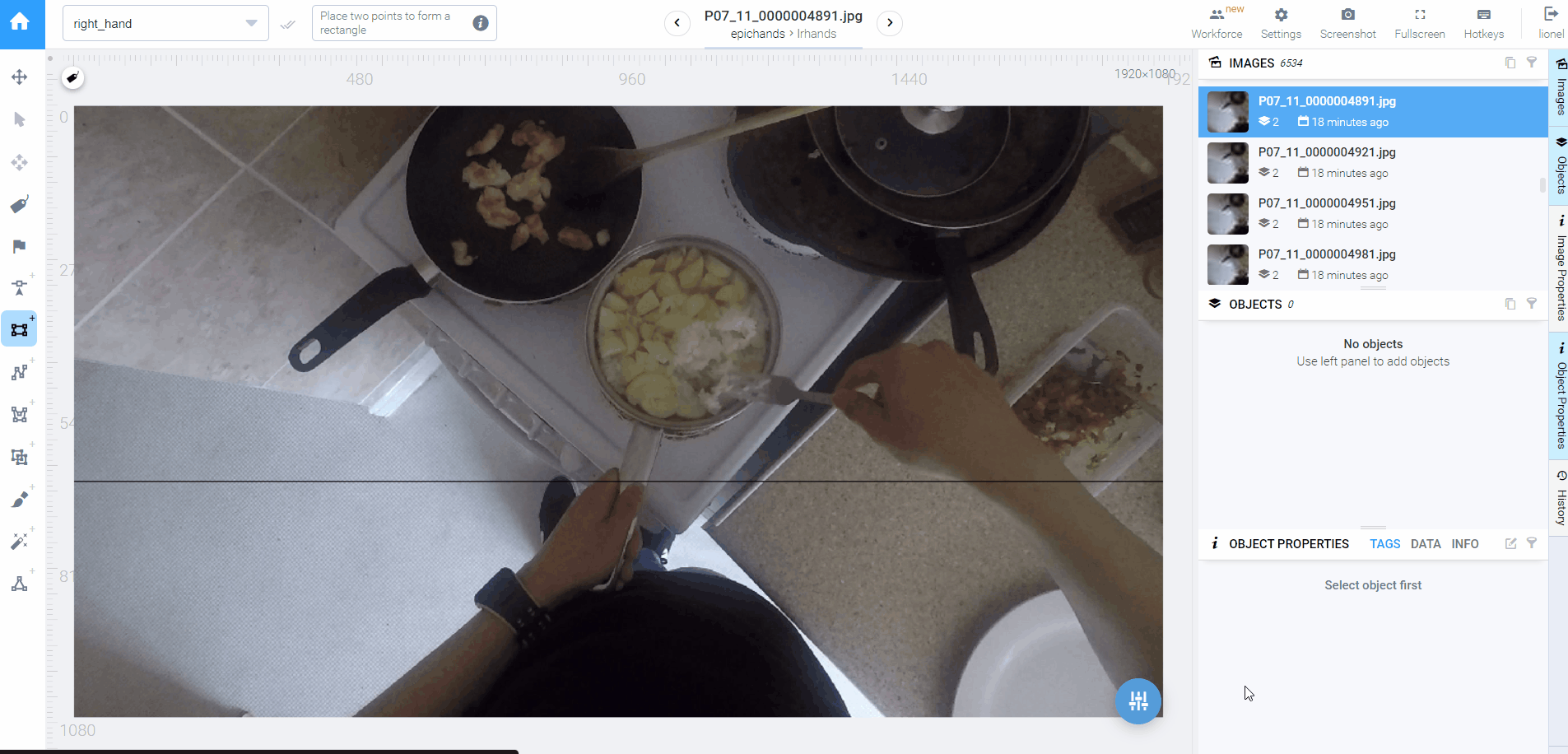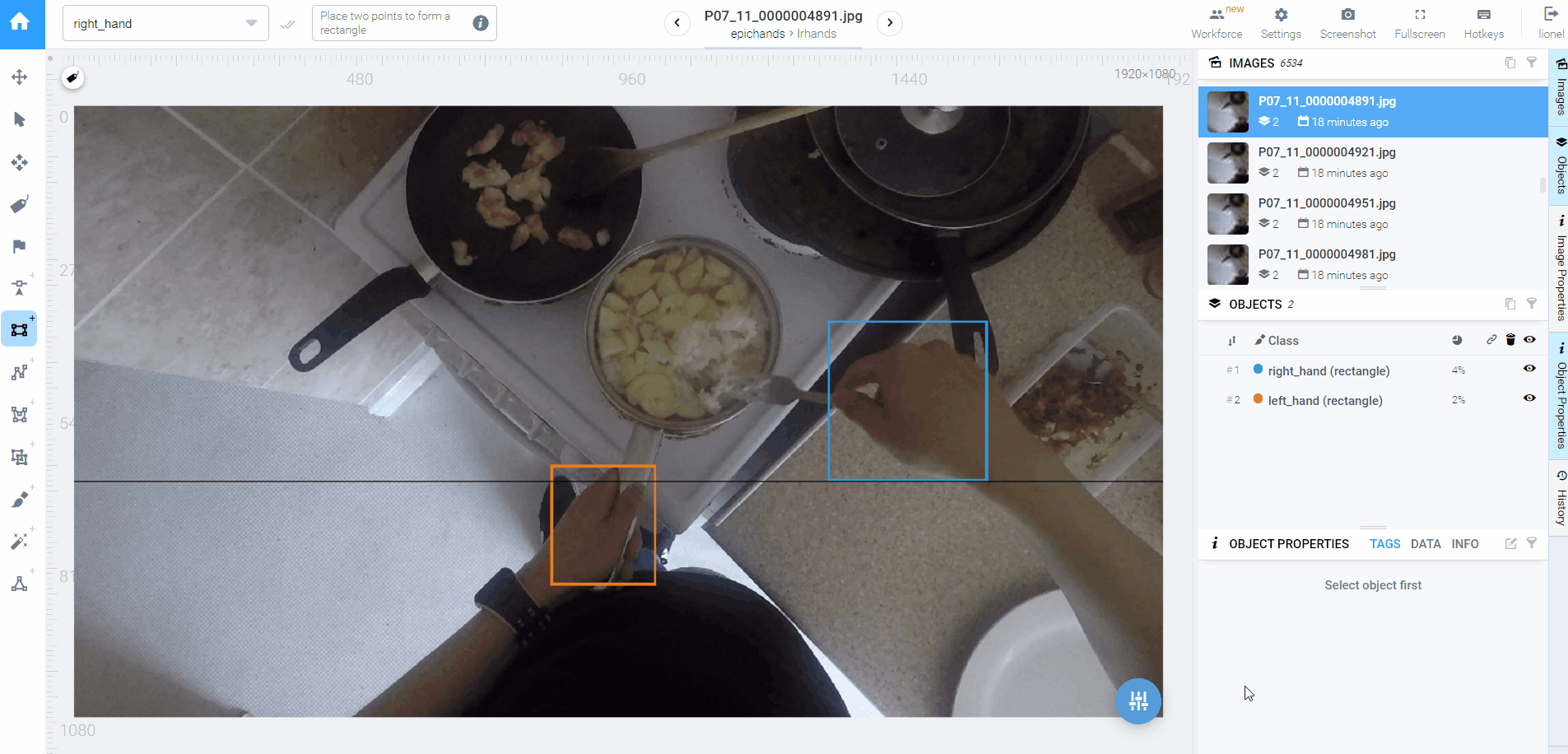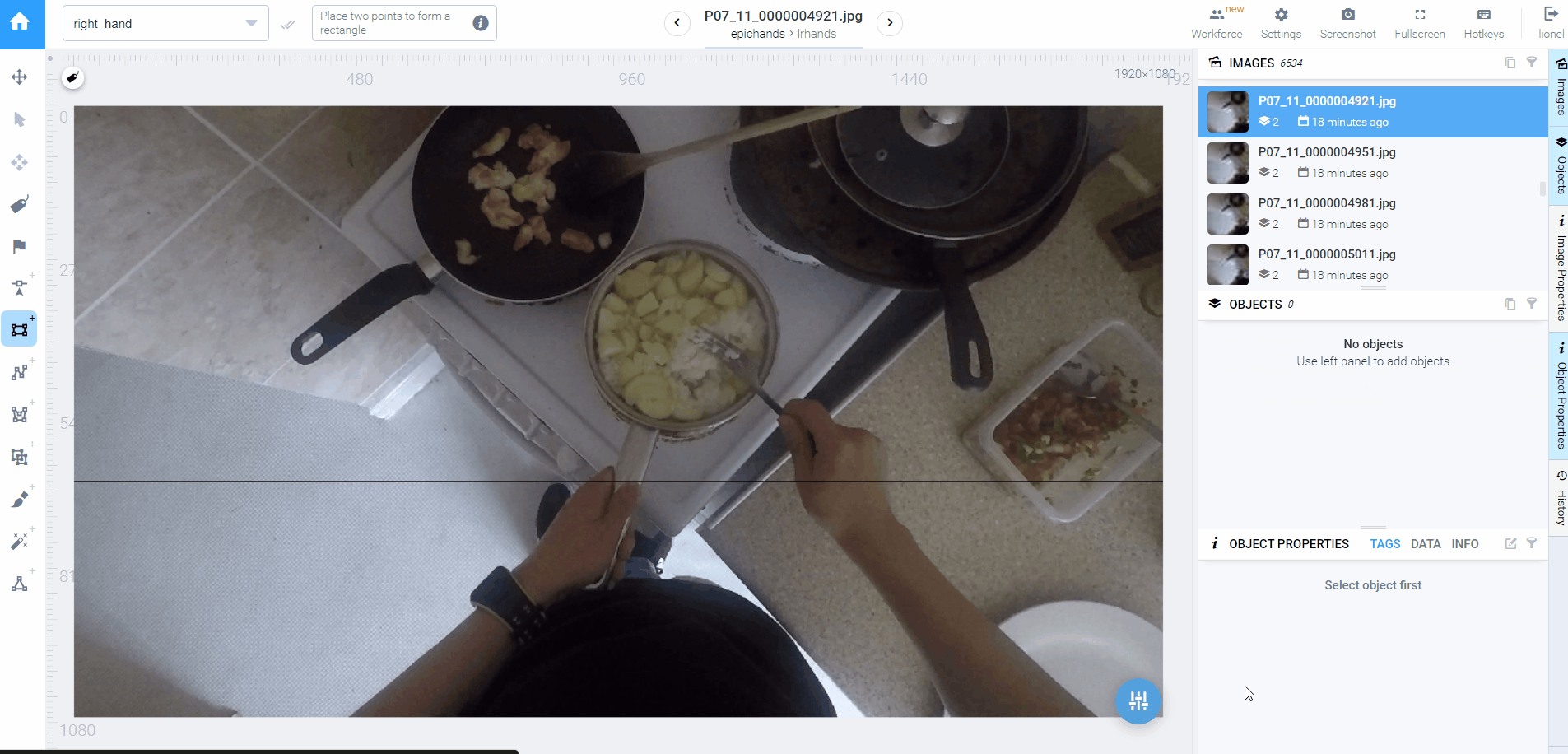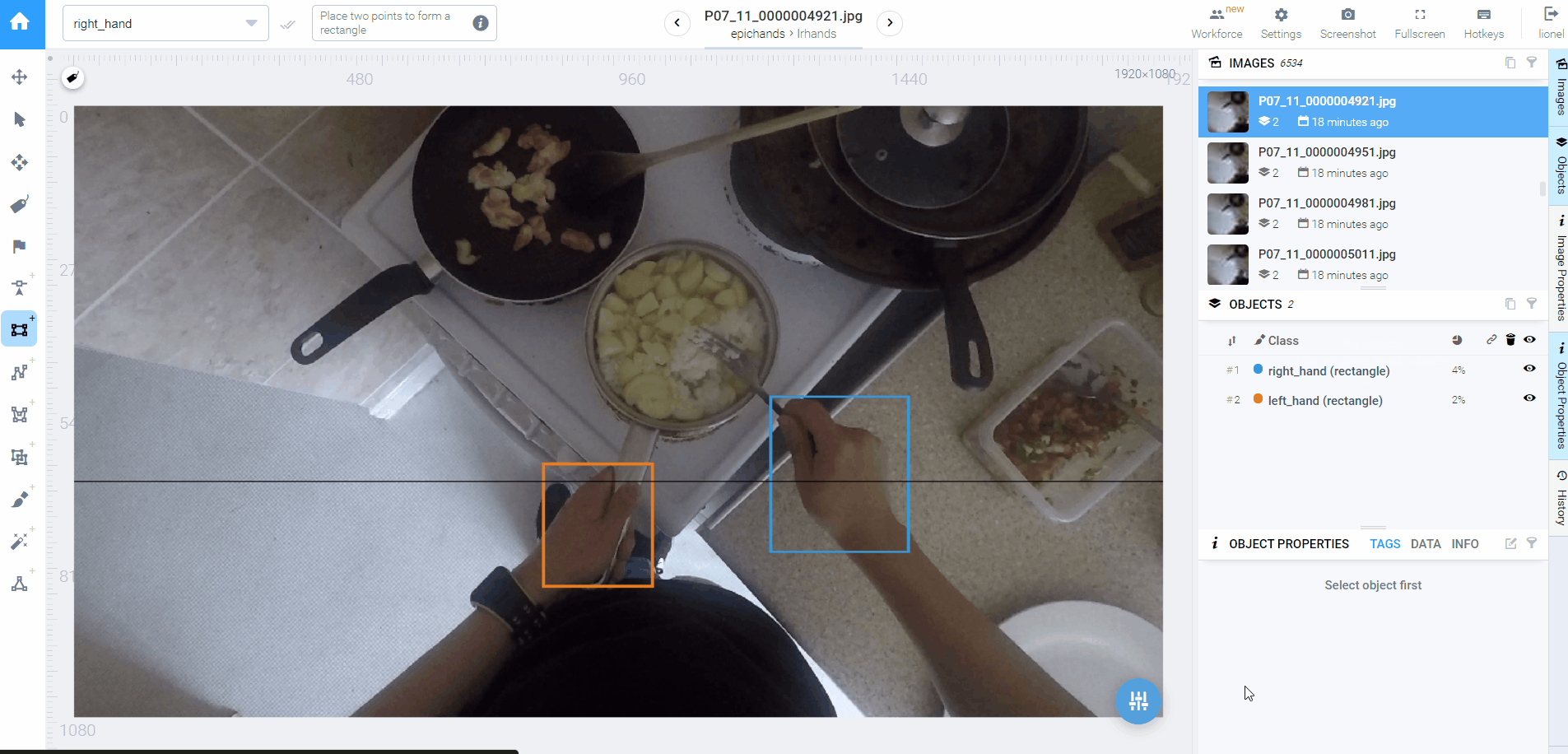
为什么出现了这么大差距?上文说过的生活节奏导致的专注时间缩水问题只是客观因素,俗话说可以克服的嘛。最主要的原因是:采用b分类器预测的标签,正确率太低!所以几乎每一张都得调整一下,很显然主要问题在第一步,我需要追赶时间。
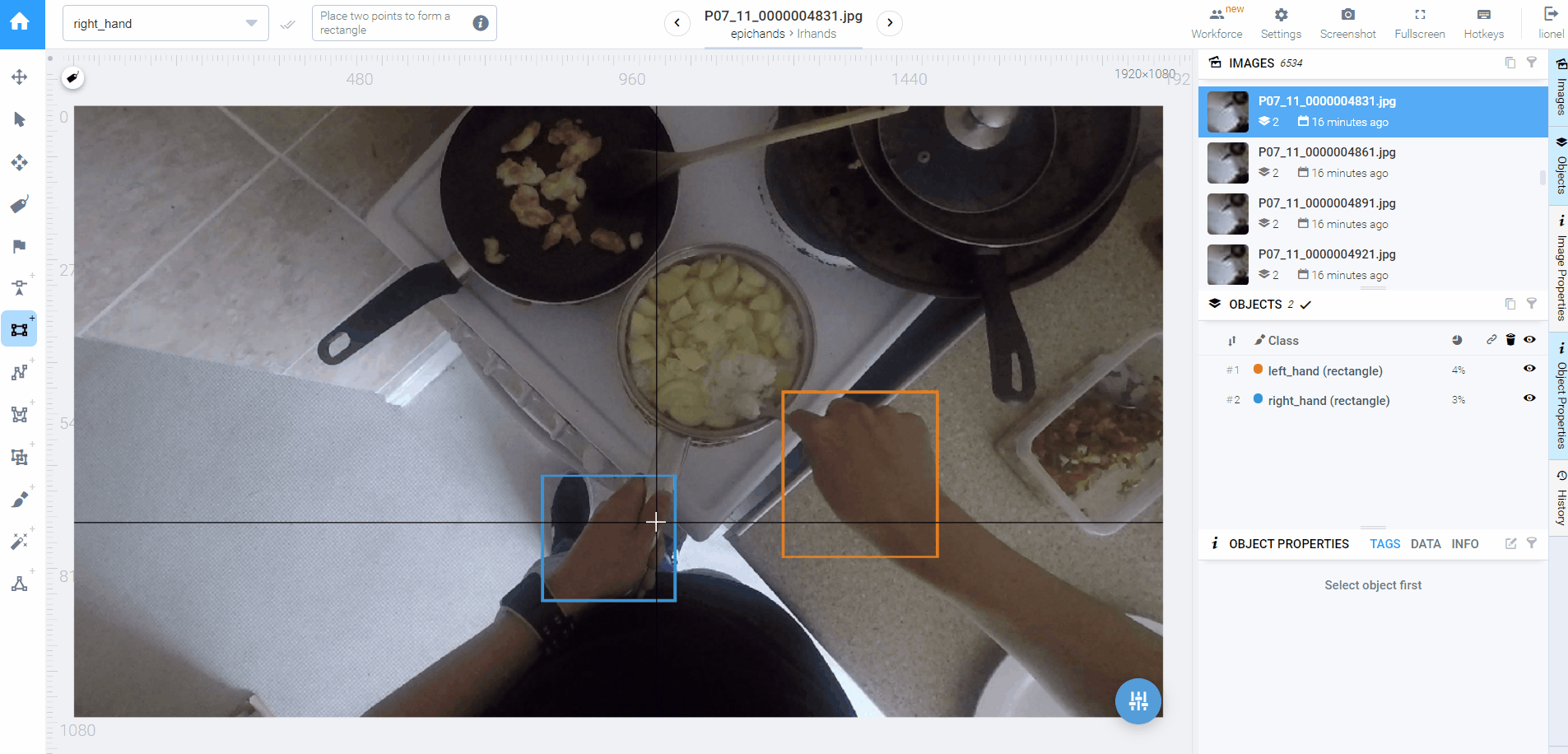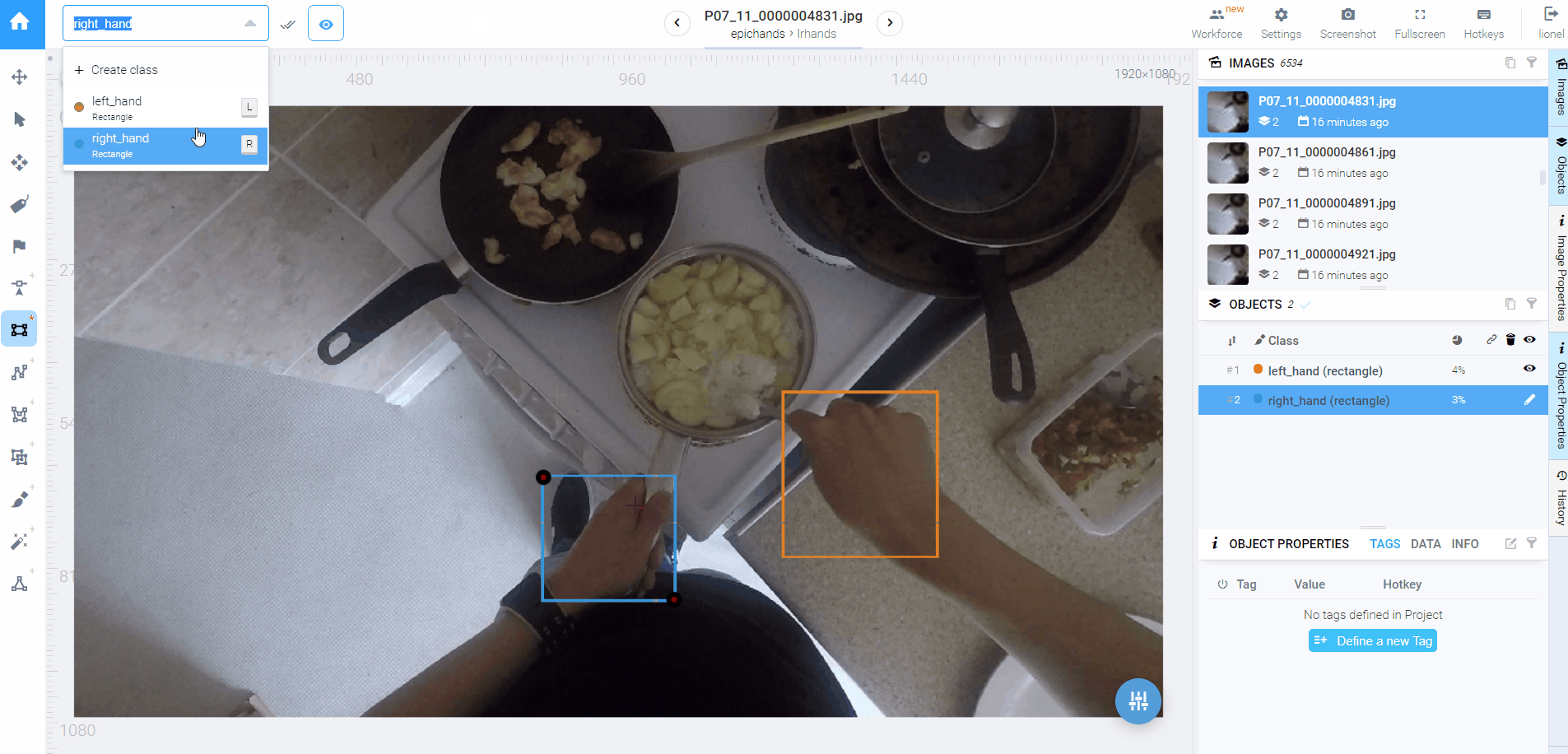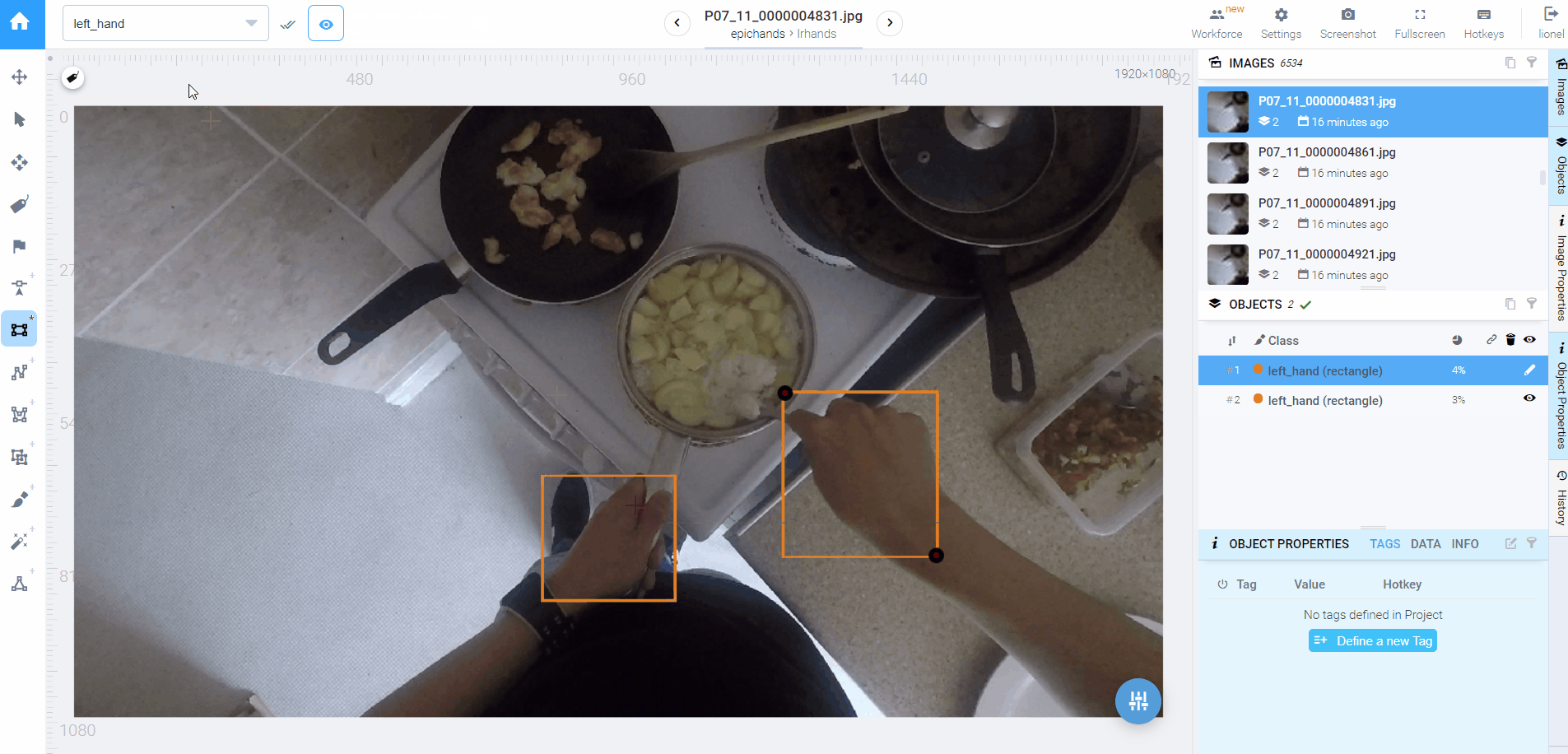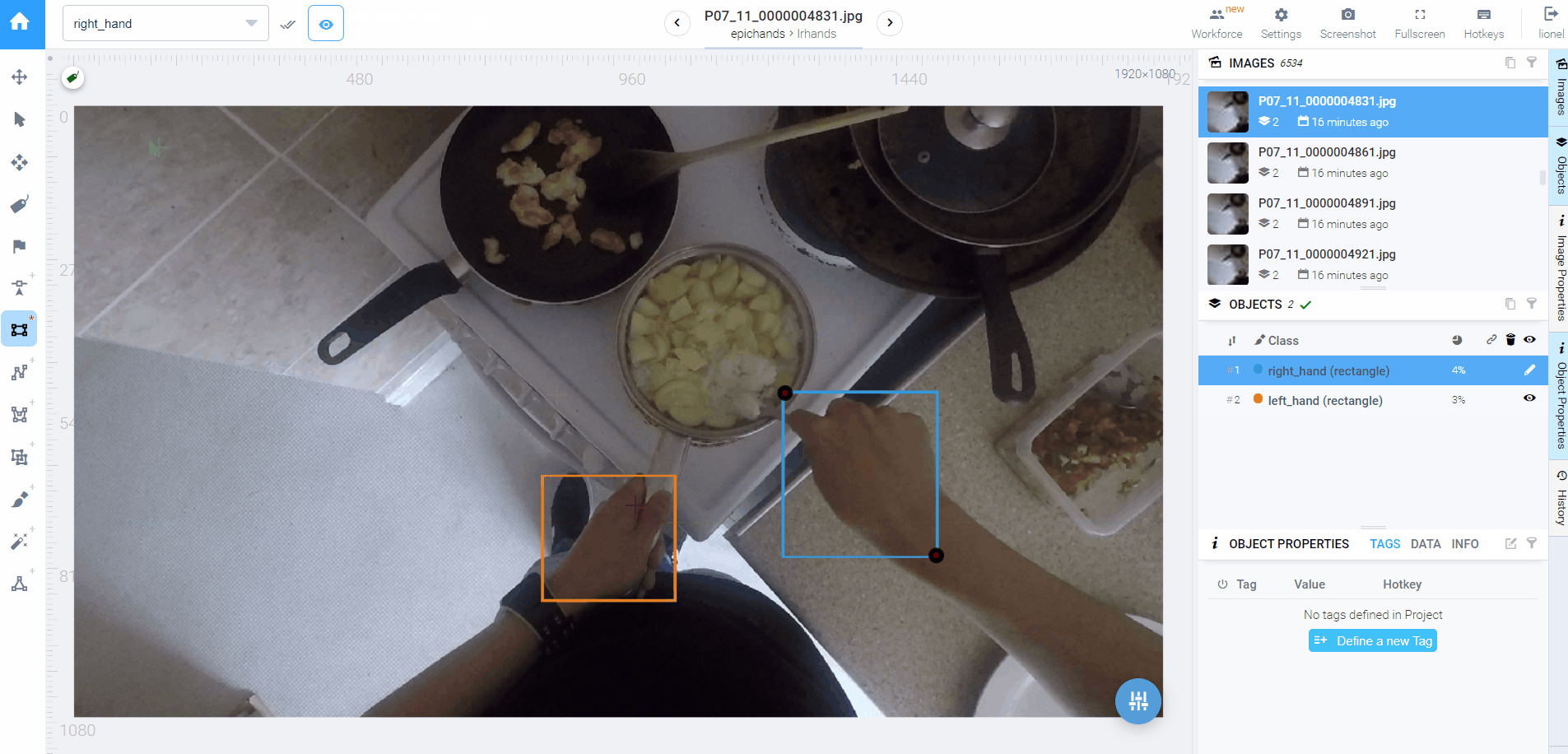 ◎ 几乎每张都要把类别倒过来
◎ 几乎每张都要把类别倒过来觉醒式补救
时间不等人,我第一个补救措施不能是优化b算法,这不符合短期利益。我在标注前6000+过程中发现,大多数都是两只手,两只手的又大多是不交叉的,这就很适合能更快能投入使用的a算法(基于相对位置关系的分类器)。所以我终于下定决心用新方法对剩下6000+标注重新分类,得到了分类正确率更高的标注。实际上我对b算法优化了之后效果也还是比a差,这个原因有他,算后话。
 ◎ 采用新策略后需要调整的标注大大减少
◎ 采用新策略后需要调整的标注大大减少除此之外,我的补救措施还包括将大任务化小:把只有一个标注框的拎出来,两个的拎出来,三个的直接检查问题(因为FPV视频不存在第三只手)。这样我可以用相同的处理方法专心处理完1863张单标注的图片,这一部分比较耗时。对于双标注的图片,我只检查非常规情况:交叉手和左右手在右左位置的情况,因为能够确定只要左手在左,右手在右,分类就肯定正确。这一步我用电脑上的看图软件快速浏览,找到非常规情况的图片ID,再去Supervisely定位到图片,手动校正。
 ◎ 分块之前需要一股脑处理6000+
◎ 分块之前需要一股脑处理6000+
 ◎ 分块之后目标也更清晰
◎ 分块之后目标也更清晰这些补救措施带来的是大大减少的工程量,之前需要投入6000的处理,变成了1900左右。剩下的6000+图片的标注校正,我只花了5个小时。
马后炮时间
总的说来,我的修改数据集任务,花了我5天,然而效率是6000+/4 days v.s. 6000+/5 hours,高下立判。差距就是:
- 是否有清醒的头脑
- 是否有更好的方法
这两个差距是怎么弥补起来的呢?是我在某天下午和妈妈打完电话吐槽这个像挤牙膏一样的任务后意识到自己需要变革。改a算法这个想法,说实话,在我干前6000+的第二天就想到了,不过碍于想着还要改代码跑代码就没实践。终于在忍不了的时候改弦更张,发现代码部分也就不到20分钟,这也说明在有好想法的时候,需要:
- 及时评估好想法的价值
- 有勇气kick off
能用上的方法都过过脑子,想想值不值得尝试,说不定就跳出了思维的禁锢,芜湖起飞。
