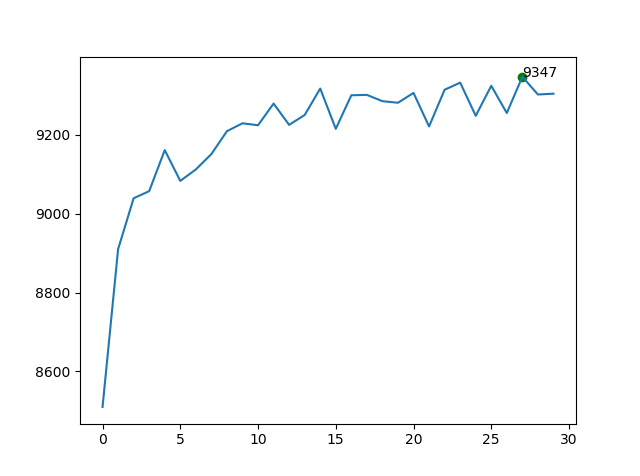
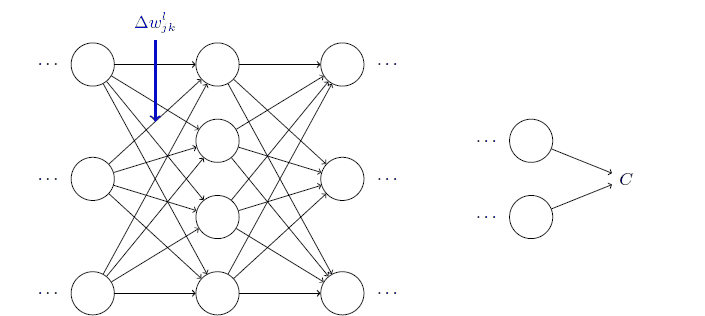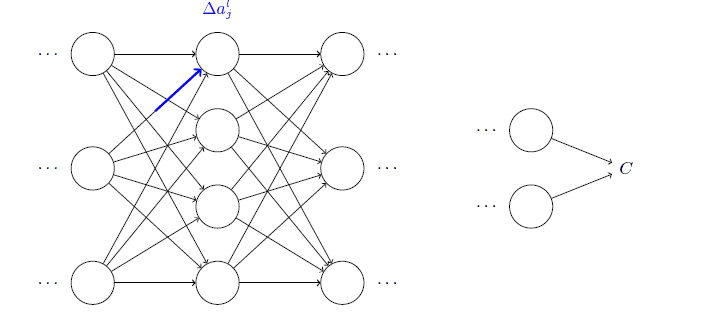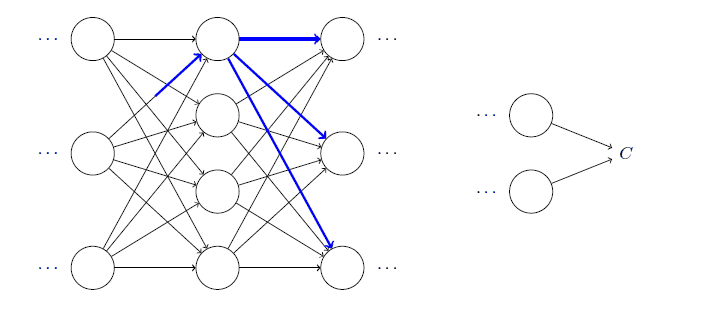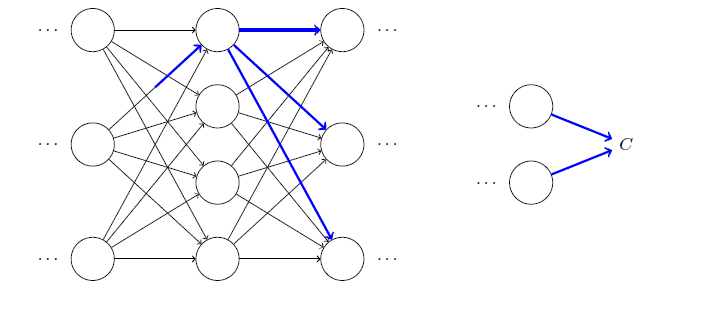
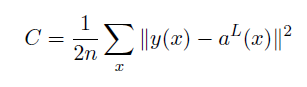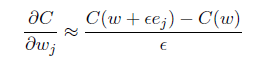defupdate_mini_batch(self,mini_batch,learning_rate):"""Update the network's weights and biases by applying
gradient descent using backpropagation to a single mini batch.
The "mini_batch" is a list of tuples "(x, y)", and "eta"
is the learning rate.
"""# Store the sum of all samples' nablasnabla_b=[np.zeros(b.shape)forbinself.biases]nabla_w=[np.zeros(w.shape)forwinself.weights]forx,yinmini_batch:sample_nabla_b,sample_nabla_w=self.backprop(x,y)# Sum updatenabla_b=[nb+snbfornb,snbinzip(nabla_b,sample_nabla_b)]nabla_w=[nw+snwfornw,snwinzip(nabla_w,sample_nabla_w)]self.weights=[w-learning_rate/len(mini_batch)*nwforw,nwinzip(self.weights,nabla_w)]self.biases=[b-learning_rate/len(mini_batch)*nbforb,nbinzip(self.biases,nabla_b)]
defbackprop(self,x,y):"""Return a tuple ``(nabla_b, nabla_w)`` representing the
gradient for the cost function C_x. ``nabla_b`` and
``nabla_w`` are layer-by-layer lists of numpy arrays, similar
to ``self.biases`` and ``self.weights``."""nabla_b=[np.zeros(b.shape)forbinself.biases]nabla_w=[np.zeros(w.shape)forwinself.weights]
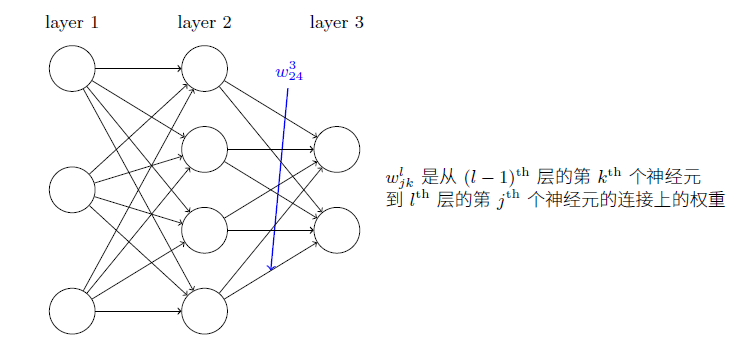
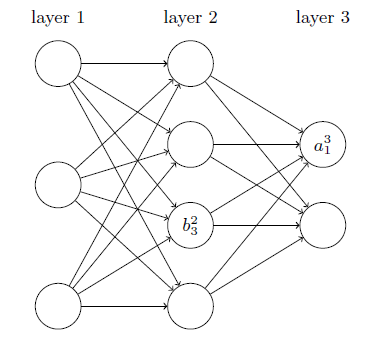
定义变量来储存每一层的最新激活值,所有激活值,以及相应的带权输入:
1
2
3
4
# feedforwardactivation=xactivations=[x]# list to store all the activations, layer by layerzs=[]# list to store all the z vectors, layer by layer
defsigmoid_prime(z):"""Derivative of the sigmoid function."""returnsigmoid(z)*(1-sigmoid(z))
然后倒数计算每一层:的代价对权重/偏置的梯度:
1
2
3
4
5
6
forlinrange(2,self.num_layers):z=zs[-l]# lth layer from the last layer, eg. l=2, the second-last layersp=sigmoid_prime(z)delta=np.dot(self.weights[-l+1].transpose(),delta)*spnabla_b[-l]=deltanabla_w[-l]=np.dot(delta,activations[-l-1].transpose())
defupdate_full_batch(self,mini_batch,learning_rate):"""Update the batch via training the full matrix of all training sample at the same time"""# Concatenate training samples# x: 784*1, full_x: 784*m | y: 10*1, full_y: 10*mfull_x=mini_batch[0][0]full_y=mini_batch[0][1]forx,yinmini_batch[1:]:full_x=np.concatenate((full_x,x),axis=1)full_y=np.concatenate((full_y,y),axis=1)# Backpropagationnabla_b,nabla_w=self.backprop_matrix(full_x,full_y)self.weights=[w-learning_rate/len(mini_batch)*nwforw,nwinzip(self.weights,nabla_w)]self.biases=[b-learning_rate/len(mini_batch)*nbforb,nbinzip(self.biases,nabla_b)]
defbackprop_matrix(self,x,y):nabla_b=[np.zeros(b.shape)forbinself.biases]nabla_w=[np.zeros(w.shape)forwinself.weights]# feedforwardactivation=xactivations=[x]# list to store all the activations, layer by layerzs=[]# list to store all the z vectors, layer by layerforb,winzip(self.biases,self.weights):z=np.dot(w,activation)+np.repeat(b,activation.shape[1],axis=1)zs.append(z)activation=sigmoid(z)activations.append(activation)# backward passdelta=self.cost_derivative(activations[-1],y)*sigmoid_prime(zs[-1])nabla_b[-1]=np.sum(delta,axis=1).reshape([-1,1])nabla_w[-1]=np.dot(delta,activations[-2].transpose())forlinrange(2,self.num_layers):z=zs[-l]sp=sigmoid_prime(z)delta=np.dot(self.weights[-l+1].transpose(),delta)*spnabla_b[-l]=np.sum(delta,axis=1).reshape([-1,1])nabla_w[-l]=np.dot(delta,activations[-l-1].transpose())return(nabla_b,nabla_w)