神经网络与机器学习二:反向传播算法如何工作。本文目的:反向传播算法数学推导和Python3实现。代码:Star
写在前面
在之前的笔记中,我对反向传播理解很浅显:预测值与真实值的误差通过神经网络反向传播到各层得到梯度(偏导数)。但是对公式背后的原理了解很不够,所以公式也记不住。
为什么要研究反向传播的数学细节?
为了李姐!上节谈到,反向传播的核心是**计算代价函数$C$对任何权重$w$(或者偏置$b$)的偏导数$\partial C/\partial w$的表达式$\nabla C$。**表达式就是代价函数的梯度,表征了代价函数在多个方向上下降是按照怎么个斜率走的,数学上指出了在改变权重和偏置的方向上,代价函数变化的快慢。反向传播让我们领悟如何通过改变权重和偏置来改变整个网络的行为。
热身:矩阵快速计算(向量化)
之前其实说过,这里目的是对符号表达更熟悉。
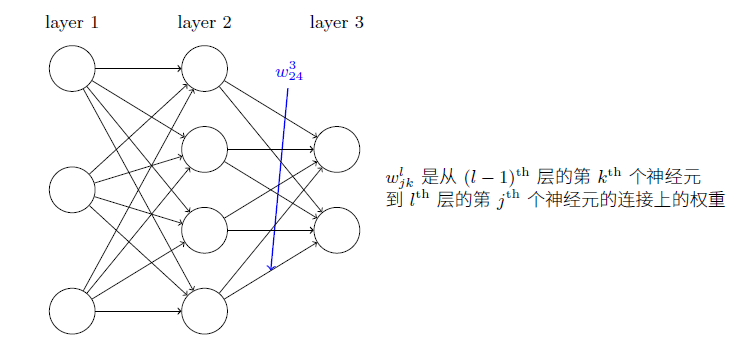
权重定义:使用$w_{jk}^l$表示从$(l-1)^{th}$层的$k^{th}$个神经元到$l^{th}$层的$j^{th}$个神经元的连接上的权重。如图:
偏置定义:使用$b_j^l$表示在$l^{th}$层的$j^{th}$个神经元的偏置。
激活值:使用$a_j^l$表示在$l^{th}$层的$j^{th}$个神经元的激活值。
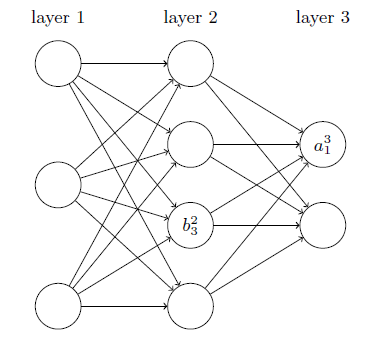
所以在$l^{th}$层的$j^{th}$个神经元的激活值$a_j^l$就和$(l-1)^{th}$层的激活值通过线性组合以及激活函数关联起来了:
$$
a_j^l=\sigma(\sum_kw_{jk}^la_k^{l-1}+b_j^l)
$$
**为了用矩阵重写以上公式**,对每一层定义权重矩阵$w^l$,它的元素是上一层连接到$l^{th}$层的神经元的权重,更确切的说,这个二维矩阵的$j^{th}$行$k^{th}$列的元素是$w_{jk}^l$。这里实际就说明了作为**行标的$j$在列表$k$之前**。一层的神经元的权重还是跟图示的神经元一样按列排布。同样对于每一层的偏置向量$b^l$,和激活向量$a^l$,就是列数为1的列向量($n^l\times 1$的矩阵)。对于向量化函数$\sigma$函数,我们用numpy实现可以自动按照元素作用(element-wise),所以直接套用。那么向量化为:
$$
a^l=\sigma(w^la^{l-1}+b^l)
$$
公式省略了写中间量带权输入$z^l=w^la^{l-1}+b^l$。
代价函数的假设
对于代价函数
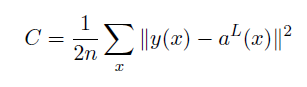
- 假设一:代价函数可以写成一个在每个训练样本$x$上的代价函数$C_x$的均值$C=\frac{1}{n}\sum_xC_x$,对于任何代价函数,不仅是二次的。原因是反向传播实际上是平均了所有训练样本的代价函数梯度。
- 假设二:代价可以写成神经网络输出$a^L$的函数。
Hadamard乘积
两同维度矩阵按元素的乘积$s\odot t: (s\odot t)_j=s_jt_j$。不同于点乘,两个同样大小的一位向量点乘结果是常数。对于Numpy来说,用*就可以了:
| |
基本方程
我们引入一个中间量:$\delta^l_j$,为在$l^{th}$层第$j_{th}$个神经元上的误差。
反向传播首先计算误差$\delta_j^l$,然后将其关联到计算梯度$\partial C/\partial w_{jk}^l, \partial C/\partial b_j^l$上。现在来理解这种误差是如何定义的。
(参照书本的描述)假设有一个调皮鬼在l层的第j个神经元上。输入进来的时候,调皮鬼搅局,私自增加很小的变化$\Delta z_j^l$在神经元的带权输入上,是的输出变成$\sigma(z_j^l+\Delta z_j^l)$,这个变化前向传播,按照微积分,最终导致整个代价改变:$\frac{\partial C}{\partial z_j^l}\Delta z_j^l$。
但是这个调皮鬼变好了,来帮忙优化代价,找到让代价更小的$\Delta z_j^l$。假如偏导数$\frac{\partial C}{\partial z_j^l}$值比较大(绝对值),那么调皮鬼选择与偏导数相反符号的$\Delta z_j^l$来降低代价。相反,如果偏导数接近0,那么调皮鬼并不能通过扰动带权输入来改善太多代价,这种情况下,神经元已经接近最优了。这里有个启发性的认识,偏导数就是神经元误差的度量: $$ \delta_j^l\equiv\frac{\partial C}{\partial z_j^l} $$
为什么不用代价对激活值的偏导?因为这样会使运算变得复杂。
以下内容将展示公式,简短证明,伪代码和Python实现
公式
输出层误差方程
$$ \delta_j^L=\frac{\partial C}{\partial a_j^L}\sigma'(z_j^L) $$
这个表达式非常自然,从上上个偏导数误差表达式由求导的链式法则得来,右边第一项表示代价随着$j^{th}$输出激活值的变化而变化的速度。当$C$不太依赖一个特定的神经元$j$时,偏导数$\delta_j^L$就会很小。第二项是导数,也就是在输出层的带权输入为$z_j^L$激活函数$\sigma$的变化速度。第一项计算只要给定了代价函数就好说,求个偏导,第二项计算更好说,代入激活函数的导数就完了。不过我们写成矩阵形式的方程(挺好理解的): $$ \delta^L=\nabla_{a^L} C\odot \sigma'(z^L) $$ 对于二次代价函数:$C=1/2\sum_j(y_j-a_j^L)^2$,有:$\nabla_{a^L} C=\partial C/\partial a^L=(a^L-y)$。
下一层误差来表示当前层误差
$$ \delta^{l}=((w^{l+1})^T\delta^{l+1})\odot\sigma'(z^l) $$
假设我们知道$(l+1)^{th}$层的误差$\delta^{l+1}$,维度为$n^{l+1}\times 1$。然后像把前向传播中把输入向前用带权传播一样,我们在反向传播中把误差反向带权传播分散开。$(l+1)^{th}$层权重矩阵转置后为$(w^{l+1})^T$,维度为$n^{l}\times n^{l+1}$。公式右侧第一个括号里的矩阵乘法结果就是$l^{th}$层的神经元的误差的链式法则的一项,即$\nabla_{a^{l}}C=\partial C/\partial a^l$,那**为什么是误差的反向传播呢?**因为之前说过误差是加在$z^l$上的,按照微积分,当前层的误差是偏导,链式法则将偏导拆成两项,误差按照激活值的线性关系反向传播(这里讲的不是很清楚,不过和输出层的一对照就清晰了)。进行Hadamard乘法的另一项就是链式法则的另一项,和输出层误差方程一样的原理。
通过已知的两个方程,我们就可以计算任何一层的误差啦。 $$ \underbrace{\delta^L\rightarrow\delta^{L-1}\rightarrow\delta^{L-2}\rightarrow...\rightarrow\delta^2}_{\text{backwards}} $$
代价函数关于任意偏置的改变率
$$ \frac{\partial C}{\partial b_j^l}=\delta_j^l $$
之前说过偏导数$\partial C/\partial z_j^l$就是误差$\delta_j^l$的度量,又$z_j^l=(w^la^{l-1})_j+b_j^l$,链式法则说明代价对带权输入的偏导和代价对同神经元的偏置的偏导是相等的。
代价函数关于任意权重的改变率
$$ \frac{\partial C}{\partial w_{jk}^l}=a^{l-1}_k\delta_l^l $$
还是利用的误差用偏导表示和利用带权输入表达式的链式法则证明的。方程说明,当输入激活值$a$很小的时候,梯度$\partial C/\partial w$也会去向很小,所以权重会缓慢学习。
当输出层激活值近似为0或者1的时候,由于激活函数导数值趋向零,所以输出层的权重学习缓慢。这样的情况,我们成为输出神经元已经饱和了,权重学习也会终止(或者学习非常缓慢)。这对输出层的偏置也成立。对于前面的层,当神经元接近饱和时,误差也可能变小,这就导致任何输入进一个饱和的神经元的权重学习缓慢。稍微总结:输入神经元激活值很低,或者输出神经元饱和,权重学习缓慢。
以上的四个方程对于任意激活函数都成立。所以我们可以使用这些方程来设计有特定学习属性的激活函数。比如说我们设计的激活函数导数总是正数且不会趋近0就可以防止神经元饱和。

简短证明
利用
代价对于带权输入的偏导数是该层的误差的度量: $$ \delta_j^l\equiv\frac{\partial C}{\partial z_j^l} $$
链式法则: $$ \frac{\partial C}{\partial z^l}=\frac{\partial C}{\partial a^l}\frac{\partial a^l}{\partial z^l}\\
\frac{\partial a^l}{\partial z^l}=\sigma'(z^l)\\
z^l=w^la^{l-1}+b^l $$
反向传播算法
对于一个训练样本:

练习:
使用单个修正的神经元的反向传播。假设我们改变前馈网络中的单个神经元,使得输出为$f(\sum_jw_jx_j+b)$,如何调整反向传播算法?
$\sigma$改$f$。
线型神经元上的反向传播。将激活函数改为$\sigma(z)=z$。重写反向传播算法。
显然,$\sigma'(z)=1$。误差一直是线性地反向传播。
对于批训练:

注意,将$\frac{\partial C}{\partial w_{jk}^l}=\delta_j^la_k^{l-1}$矩阵化时,由于右侧维度分别为$n^l\times 1$和$n^{l-1}\times 1$,所以将后面的转置。
代码
首先回顾一下上一章没仔细讲得update_mini_batchdai方法:
| |
首先创建了nabla_b, nabla_w来分别作为初始化为零的$\partial C/\partial b$和$\partial C/\partial w$,它们都是列表,列表的每一项是一个Numpy数组,维度各不同(按网络结构来),储存权重和偏置。然后我们将求和过程融入对批数据的样本循环中,每一次输入样本,反向传播得到这个样本的梯度值$\partial C_x/\partial b$和$\partial C_x/\partial w$,它们俩和之前的储存整体梯度的两个变量维度相同,所以可以通过列表循环累积起来存入整体梯度。每遍历完一个批数据之后,将整体梯度求平均值,然后进行梯度下降更新参数。
下面来实现反向传播方法,即
| |
先创建和self.weights,self.biases同样维度的样本代价梯度变量:
| |
定义变量来储存每一层的最新激活值$a^l$,所有激活值$[a^1,...a^L]$,以及相应的带权输入$z^l$:
| |
进行前向传播,也就是遍历每一层,可以遍历权重/偏重实现:
| |
反向传播时,先计算输出层误差$\delta^L=\nabla_{a^L}C\odot\sigma'(z^L)=(a^L-y)\odot\sigma'(z^L)$,然后计算输出层的代价对权重和偏置的偏导:
| |
$\sigma'(z)=\sigma(z)(1-\sigma(z))$
1 2 3def sigmoid_prime(z): """Derivative of the sigmoid function.""" return sigmoid(z) * (1 - sigmoid(z))
然后倒数计算每一层:$L-1, L-2, L-3,...$的代价对权重/偏置的梯度:
| |
最后返回值:
| |
批训练的反向传播全矩阵方法
实现完毕,来思考一个问题。上面在实现SGD优化方法时,是对小批量数据的训练样本进行遍历。可以让神经网络同时对小批量数据的所有训练样本进行梯度计算,也就是用一个矩阵作为输入:$X=[x_1, x_2, ..., x_m]$,每个列向量就是一个训练样本,通过同样的原理进行前向传播和反向传播。
全矩阵方法
伪代码:
- 输入:$X=[x_1, x_2, ..., x_m]$作为$a^1$。
- 前向传播:对每个$l=2,3,...,L$计算相应的$z^l$和$a^l$。
- 输出层误差$\delta^L$。
- 反向误差传播:对每个$l=L-1,L-2,...,2$,计算$\delta^l$。
- 计算代价函数对权重和偏置的梯度。
- 梯度下降,需平均梯度因为求出的梯度包括多个样本。
整理输入输出格式:
单个样本是$x:(784\times 1)-y:(10\times 1)$的,我们要把第二个维度展成一个小批量数据的大小,即:$X:(784\times m)-Y:(10\times m)$。接着我们使用稍作修改的反向传播函数,它的输出结果依然是和神经网络的权重和偏置一样维度的梯度。
| |
修改反向传播函数:
首先定义储存梯度的变量,和网络参数同维度。然后进行一次前向传播,这时就要注意维度对应了。对于每一层有这样两次运算:
$$
z^l=w^la^{l-1}+b^l\\
a^l=\sigma(z^l)
$$
那么假设小批量数据大小是$m$,第二层大小是10,那么对于第二层的$w^la^{l-1}$,维度操作是$(30\times 784)\times(784\times m)=(30\times m)$,结果是$m$个列向量,对于每个列向量,对应位置应该加上对应偏置,这对$m$个列向量都是一样的,所以所有列向量相同位置应该加上相同偏置:
$$
{w^l}\cdot{^ia^{l-1}}+^ib^l=\\
\left[\begin{matrix}
{w^l_{1}}\cdot ^1a^{l-1} & {w^l_{1}}\cdot ^2a^{l-1} & \cdots & {w^l_{1}}\cdot ^ma^{l-1}\\
{w^l_{2}}\cdot ^1a^{l-1} & {w^l_{2}}\cdot ^2a^{l-1} & \cdots & {w^l_{2}}\cdot ^ma^{l-1}\\
\vdots & \vdots & \ddots & \vdots\\
{w^l_{n^l}}\cdot ^1a^{l-1} & {w^l_{n^l}}\cdot ^2a^{l-1} & \cdots & {w^l_{n^l}}\cdot ^ma^{l-1}
\end{matrix}\right]
+\left[\begin{matrix}
b_1^l & b_1^l & b_1^l & b_1^l & b_1^l \\
b_2^l & b_2^l & b_2^l & b_2^l & b_2^l \\
\vdots &\vdots &\vdots &\vdots &\vdots \\
b_{n^l}^l & b_{n^l}^l & b_{n^l}^l & b_{n^l}^l & b_{n^l}^l
\end{matrix}\right]
$$
所以需要把$(30\times 1)$的偏置矩阵重复$m$次得到$(30\times m)$的偏置矩阵。
反向传播时,要求出每一层的误差$\delta^l$,误差的维度为$(n^l\times m)$,代表$m$个误差列向量$[^1\delta^l,^2\delta^l,\cdots,^m\delta^l]$,对应每个样本,如果要展示这个小批量数据的整体梯度,就得把列向量平均成一个列向量,可以先求和,平均化在更新参数时再做。那么对于偏置,只需要$(n^l\times 1)$的,就直接用此层求和的误差$sum(\delta^l, axis=1)$代替;对于权重,有$\partial C/\partial w^l=\delta^l\cdot(a^{l-1})^T=(n^l\times m)\times(m\times n^{l-1})$,直接使用该层误差(不缩成一列),而实际上这样的计算实际上就是$m$个$^i\delta^l\cdot {^i(a^{l-1})^T}$对应位置的求和,所以最后也需要在更新参数时候做平均。
| |
实验效果对比
设置随机种子,便于控制变量:
| |
网络结构均为$[784,30,10]$,迭代期30,小批量数据大小为10,学习率为1.8。
全矩阵mini-batch SGD方法
| |
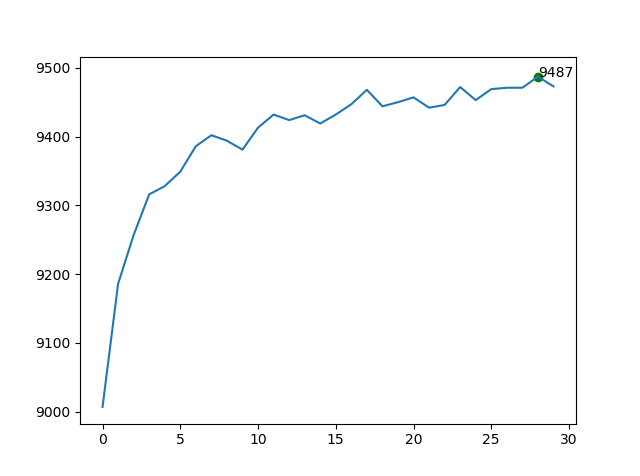
非全矩阵mini-batch SGD方法
| |
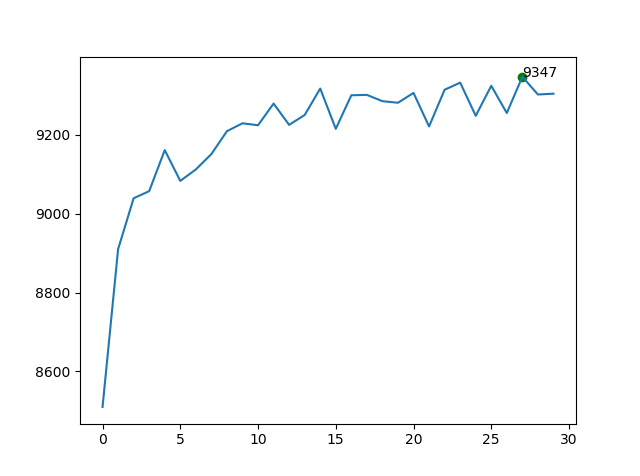
对于运算速度,在我的电脑上全矩阵方法几乎是非全矩阵的三倍快。最终的识别率也差不太多,甚至全矩阵方法还稍微高一些。作者指出,现在SOTA的方法基本上都采用了全矩阵方法。
反向传播为什么快
要和传统的极限方法求偏导数的方法进行对比,传统的计算梯度常常是利用极限近似:
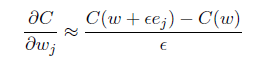
公式比反向传播的四个方程简单多了,但是计算一个权重的偏导需要计算两次前向传播,1,000,000个权重就是1,000,001次前向传播,远远大于反向传播方法的一次前向传播和一次后向传播。反向传播聪明就在于在一次后向传播时同时计算所有的偏导数。实际上,一次后向传播的计算消耗和一次前向传播差不多。
抛开公式全局理解
思考两个问题:1)这个算法真正在干什么?2)那些人是怎么发现反向传播的?
假设在某个权重上加上了一点变动,那么这个变动就会沿着网络分摊到直接连接的激活值以及后面层所有的激活值上去。所以计算$\partial C/\partial w_{jk}^l$就是在细致地追踪一个$w_{jk}^l$的微笑改变是如何导致$C$的变化值。可以分析得到,某条路径上的变化率因子就是路径上子路径的变化率银子的乘积,这是基于链式法则的。而由最终层到某一个权重上,有很多种路径,由于这样的路径对应的变化率,是具有叠加性的,所以反向传播就相当于计算所有可能的路径的变化率之和的过程。
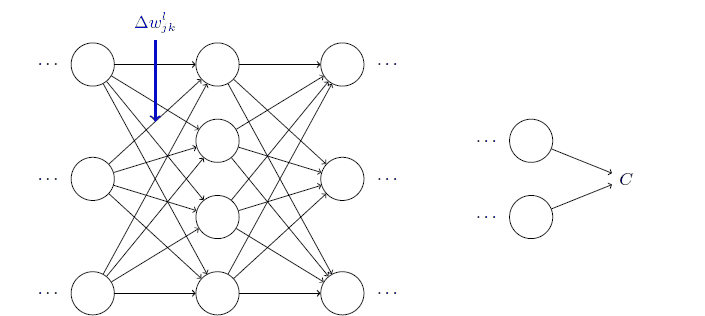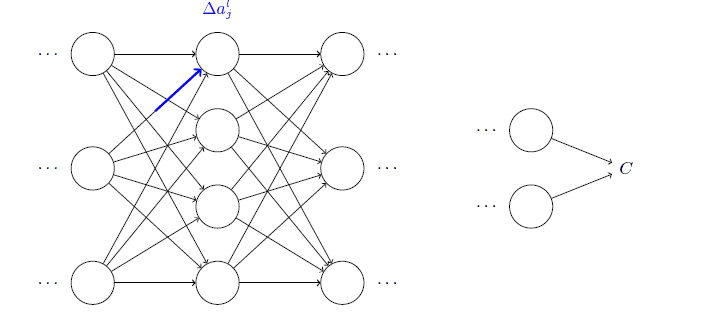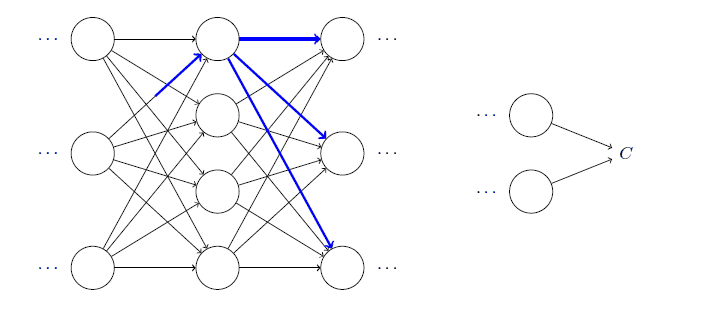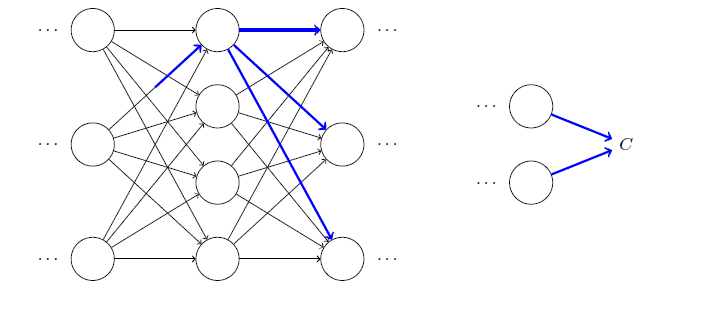
发现反向传播的过程考察了大量繁杂的数学证明,其实基本知识都离不开偏导、求和,很考验耐心,说明了大量证明工作积累的价值。
总结
回想这一章的目的:反向传播的数学原理和代码实现,我发现都完成了,并且在数学原理上花了大量的笔墨。证明过程不是通过单独列出一节展示推导过程给出,而是每给出一个方程,辅以适量的文字和公式来说明意义和原理。根据最后一节抛开公式全局理解,也应该清楚反向传播的过程就是基于偏导和链式法则来追踪代价函数如何对某一权重变化率而变化。特别的,这里再放出四个方程:
反向传播的结果就是整个训练集的(近似)梯度,每一次更新参数的时候,按照下面的方程:
$$
w^l \gets w^l-\frac{\eta}{m}\frac{\partial C}{\partial w^l}\\
b^l \gets b^l-\frac{\eta}{m}\frac{\partial C}{\partial b^l}
$$
这里的近似梯度$1/m\frac{\partial C}{\partial w^l},1/m\frac{\partial C}{\partial b^l}$都是指当前训练方法下,所有参与一次参数更新的训练样本的计算的梯度的平均值。如我们按照非全矩阵方法SGD:小批量数据的每个样本计算梯度,然后平均值作为全矩梯度的近似。全矩阵SGD方法同时计算小批量数据中所有样本的平均梯度。全矩阵方法由于矩阵计算的优点,训练速度要快很多(对于MNIST手写数字识别任务,我电脑上全矩阵方法时非全矩阵方法的约3倍快),现在大部分的优秀算法都在使用它。