Redmon, J., Divvala, S., Girshick, R. and Farhadi, A., 2016. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 779-788).
Abstract
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimised end-to-end directly on detection performance. Our unified architecture is extremely fast. Our base YOLO model processes images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO, processes an astounding 155 frames per second while still achieving double the mAP of other real-time detectors. Compared to state-of-the-art detection systems, YOLO makes more localisation errors but is less likely to predict false positives on background. Finally, YOLO learns very general representations of objects. It outperforms other detection methods, including DPM and R-CNN, when generalising from natural images to other domains like artwork.
Aim
This paper aims to build an object detection algorithm to directly output bounding boxes and corresponding classes from image pixels. Previous out-of-the-state methods, like (Deformable Parts Model) DPM, Fast R-CNN involve complex processing flowlines, which are time-consuming and difficult to optimise.
Summary
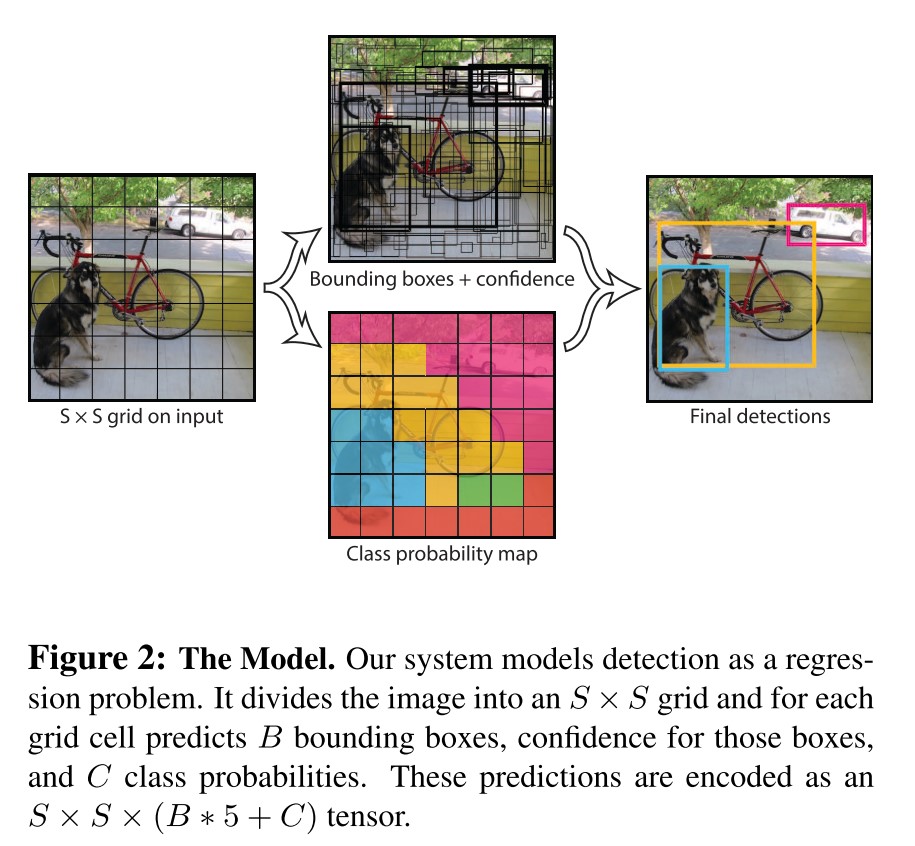
Generally, unlike previous classifier-based works, YOLO integrates the complex pipeline into one unified model trained on a loss function. Firstly, the input image is divided into an S*S grid. The grid cell is aimed to detect the object whose centre falls into the cell. Every grid cell predicts B bounding boxes and their confidence scores, which are the products of the probabilities of the objects and the IOU (intersection over union) between the predicted boxes and the ground truth boxes. Moreover, C conditional class probabilities are predicted for each cell. Each cell finally predicts a set of probabilities of classes.
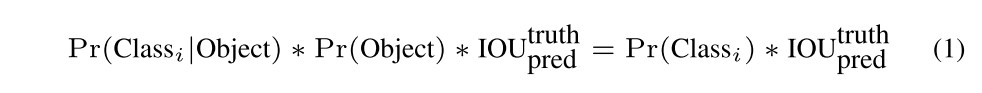
Such a scoring function encodes both class probabilities and how well the proposed boxes fit the objects. When the authors evaluated YOLO on PASCAL VOC dataset, they used S=7, B=2 and C=20, and made the final prediction an
The network is a convolutional neural network. The initial 24 convolutional layers extract features from the image while the subsequent two fully connected layers predict the output probabilities and positions. A faster version: Fast YOLO has only nine convolutional layers while the training and testing parameters remain the same.

When the authors train the network, they pretrain 20 convolutional layers on the ImageNet 1000-class competition dataset. Then they convert the model by adding four more convolutional layers and two more fully connected layers to perform detection. Sum-squared error is easy to optimise, but it assigns weights to localisation error equally with classification error. This issue can overpower the gradient from cells that contain objects, leading to model early diverge in training. Therefore, they weighted more in terms of predicted bounding box coordinates and less in boxes that don’t contain objects. Finally, they train the network for about 135 epochs in training and validation datasets from PASCAL VOC 2007 and 2012.
In terms of experiments, they implemented explorations in four aspects. The first one is the comparison between YOLO and other real-time detectors on PASCAL VOC 2007. The second one is to analyse the errors made by YOLO and Fast R-CNN on PASCAL VOC 2007. And they found the combination can reduce errors from background false positives. Thirdly, they experimented on current state-of-the-art methods to compare mAP on VOC 2012. Finally, they used YOLO to detect the person in artworks and demonstrates YOLO’s great performance in generalisation.
Review
Why I chose the paper?
I choose this paper because it is one of the most recent state-of-the-art object detection algorithms. One of my work is to implement the third version of YOLO model on PyTorch and understanding YOLO is the basis of understanding YOLO v3.
Advantages
It implements a simple structure of the neural network, which proposes bounding boxes with confidence rates from only one evaluation. This single network makes it very convenient to be optimised. Then the algorithm is extremely fast. The algorithm can process images at 45 fps for base YOLO model and 155 fps for fast YOLO model. Secondly, YOLO makes much less mistakes in background patches in an image. It is reasoning globally about the image, encoding contextual information about the objects. In terms of generalisation, it also outperforms other methods like DPM and R-CNN. This advantage is more significant while testing the algorithm on artworks using the model trained on natural images.
Shortcomings
The most significant disadvantage of YOLO lies in its accuracy. The algorithm still finds it hard to make accurate localisation of some objects, especially small objects. Since YOLO use grid cells to predict bounding boxes, small objects in groups are very hard to be detected. The loss function treats errors equally in all bounding boxes, which makes the small error more detrimental in small boxes.
Generally, this is an outstanding object detection algorithm, which is one of the fastest methods among the state-of-the-art works. However, the most significant drawback is that it is not very precise. The author addressed this issue later by making little changes to the network and improved the accuracy. The author is rather honest when he made an assessment of YOLO’s performance on benchmarks. He clearly denoted the negative side of the model, which makes it easier to compare them between other algorithms.
