Google Colab终究是一堆槽点,布大提供了超级计算机BlueCrystal Phase 4来服务研究人员的计算任务,本文就详细讲述如何在自己的电脑上使用这个珍贵资源。注:文章围绕Windows展开,不过差别不大,其他机型可以参考链接和引用解决。
Google Colab提供的GPU资源我在三到五月间用了几次,用来训练YOLOv3模型,成功训练出来的是两次,分别是训练16张COCO数据集[1]和700多张的自标注数据集[2],前一个好说,数据集小训练得飞快,后一个训练简直是损耗我的耐心,过程中出现了一些印象深刻的坑:
允许一次持续使用免费GPU最多12小时。我最多一次用了8小时,虽说没达到12小时,但是我印象深刻,因为数据集再大一倍就不是8小时了,需要加上checkpoint让模型能在下一次免费的12小时内继续训练。
[Updated 2020.7.17]昨天到今天用Colab训练了自己的数据集,8000+的训练图片,同时也包括每一个epoch的验证,batch-size为8,一共100个迭代期,结果12个小时用完只训练到第19迭代期,这种时候可以采取一些小trick来解决[3]。
GPU资源的运算能力并不是很大。就拿我用的代码来说,作者采用的
batch-size达到了16或者32,然而我的情况是8就是运算极限了,得继续缩小为4。挂载断开连接。这是一大坑,Colab可能因为各种原因disconnected,比如电脑自动休眠,窗口和鼠标长时间不活跃等。有一次不知道是因为反复重复连接GPU还是怎么的,Colab不让我连了,我只好换了个账号训练,有号任性。解决的办法也有,让电脑尽量插电不息屏,设置浏览器的js自动点击或者使用按键精灵。
量大的文件位置得上传。我是上传到Drive然后在Colab里面开头mount Drive,为什么要这么麻烦呢?就是因为Colab的临时空间只有30多G,使用COCO的话先下载压缩包,20G没了,然后解压,解压过程是不能删压缩包的,所以存储必超。另一个问题就是即使数据集小能塞进临时空间,但是重连GPU之后临时空间会消失......网速慢的时候,这个问题会搞人。
但是还是觉得Google很棒,能提供免费的GPU资源给学生党用。后来,RRP老师Richards在我的Research Plan里的关于使用Colab的risk分析处给了个评语:UoB HPC?我当时没搞明白他写啥也没去查,后来跟导师反映计算资源的时候直到了布大给的BlueCrystal Phase 4 (BC4)。直到今天申请的时候才知道就是HPC提供了BC4。布大的HPC拥有BlueCrystal超级计算机,BlueCrystal Phase 3 (BC3)和BC4都在2013年和2016年的超算500强里,今年没上榜但是要帮忙训练个模型不是绰绰有余?BC4有将近16,000核和64个NVIDIA P100 GPUs,运算速度能达到600万亿次。BC3适用于一般的单处理器和小型的并行运算,BC4就是用来做大型并行运算的,这些术语我并不是很在行,但是加上导师的推荐,想来训练大型CNN模型应该是要用BC4。
HPC的管理员也是这么说的:
I've created accounts for you on Bluecrystal Phase 3 and 4. Since you'll be running computer vision and NN jobs I would recommend using Bluecrystal 4.
The GPU hardware and software stack is much more up to date on there.
 ◎ Credit: https://www.flickr.com/photos/9123851@N03/2610243074
◎ Credit: https://www.flickr.com/photos/9123851@N03/2610243074下面就介绍一下布大做项目的学生如何申请资格用上曾经的超算500强。
注:1. 带*号的目录必看或者必须参考配置。2. 用VPN来使用BC4训练的时候不要开其他占用网络的。
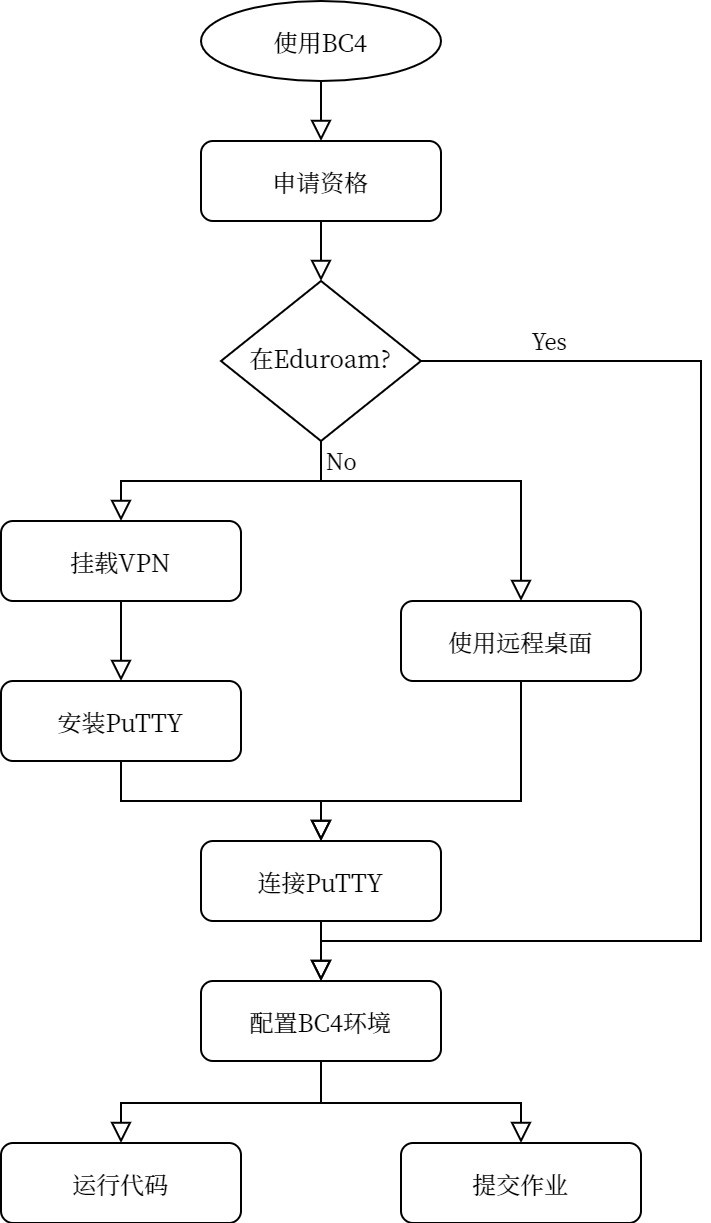
配置连接
申请资格
首先在 https://www.acrc.bris.ac.uk/acrc/phase4.htm 网页看看大致的介绍,左侧菜单有Application Form,申请表除了需要基本学生个人信息外,还需要Project Code,这个需要找导师要。填好提交后等待消息。邮件回复开通资格后,就可以进行下面的步骤了。
VPN
N.B. 如果是在校园网Eduroam环境下使用电脑,不需要配置VPN。
https://www.bris.ac.uk/it-services/advice/homeusers/uobonly/uobvpn
选择相应的系统,比如Windows 10,下载Big-IP Edge客户端并安装。从启动页打开客户端启动连接。
远程桌面环境
N.B. 如果是在校园网Eduroam环境下使用电脑,不需要配置远程桌面环境。
http://www.bristol.ac.uk/it-services/advice/homeusers/remote/studentdesktop
一般来说选择第一中connection下载,点击之后输入UoB的账号密码就可以连接上UoB的桌面了。
PuTTY
N.B. 如果是在远程桌面环境下,不需要安装PuTTY。
[Updated 2020.7.18]PyTTY有个糟糕的问题:容易掉线...所以就得常常盯着它然后等掉线再重启。
https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html,直接选择64-bit的msi文件下载安装。
点击PuTTY启动,在主页面的Host Name输入:
bc4login.acrc.bris.ac.uk
# GPU: bc4gpulogin.acrc.bris.ac.uk
注:不要在GPU组上直接跑训练代码!特别是大型数据集的训练,会占用很大的内存。正确做法是使用排队系统提交作业。
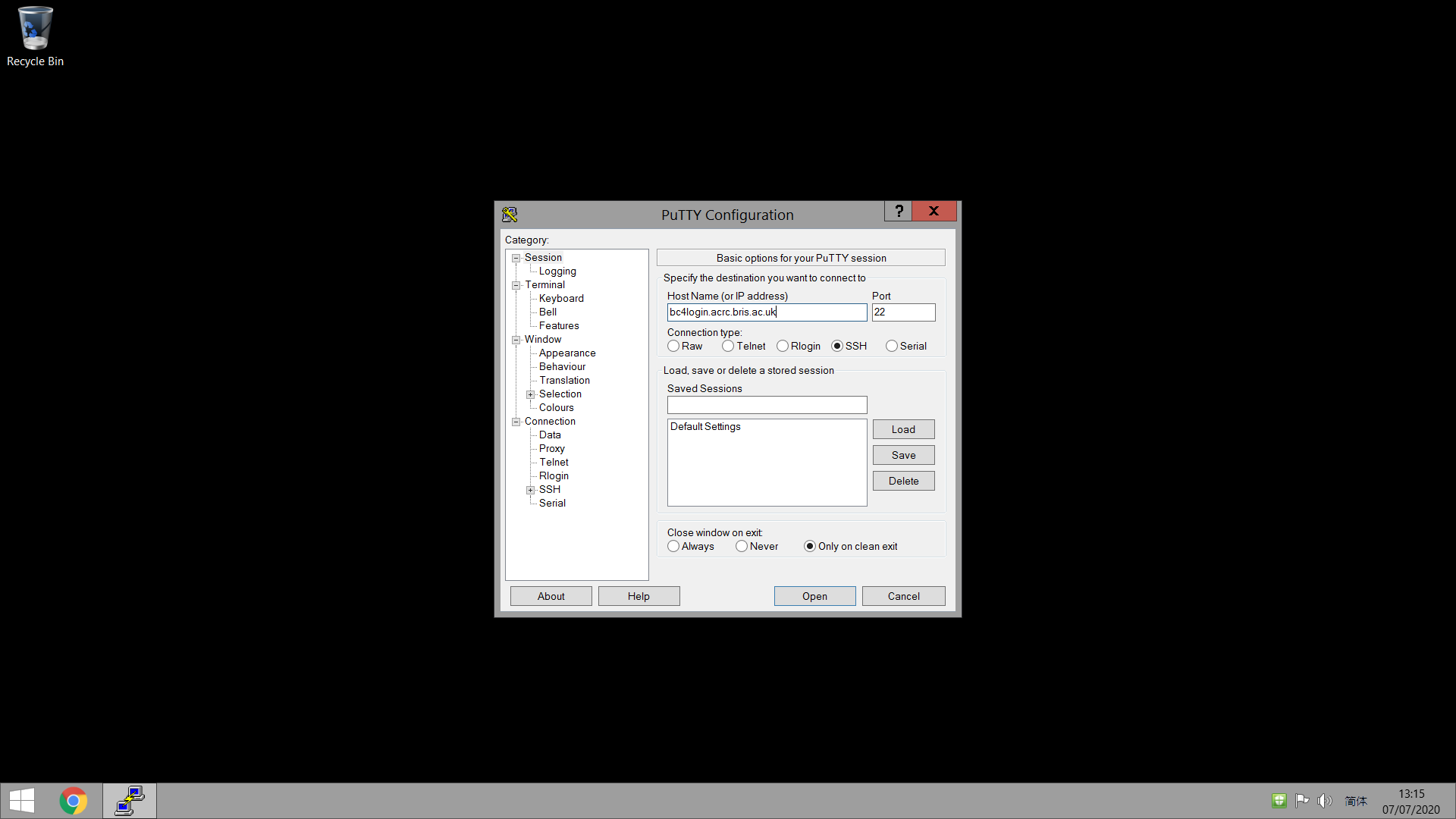
点击Open,按照要求输入UoB账号和密码。
配置BC4
官方文档: Blue Crystal Phase 4 User Documentation
了解BC4存储
Link。包含Home Directories和Scratch Space两种空间,前者是固定的20G,后者是512G,用于大型数据集的输入输出,后者路径为/mnt/storage/scratch。这些控件都不会备份。下面探索一下存储空间,会用到Linux命令[4](我当年怎么就没好好学呢),BC4的Linux shell默认是常见[5]的Bash(在申请资格的时候选择)。
现在检查一下我的存储容量:
| |

使用量在blocks一栏,总容量在quota一栏。根据文档,容量采用软限制,超量将limit一栏修改。所以大概就能猜到home 存储空间就是这样按照每个人的ID分开的,每个人的Home directory有20G可用,BC4会监控存储空间大小,一旦超过上限,是通过一个标志位控制是否还有资格继续储存文件。
我需要在BC4上跑NN模型,那么源代码就存储在home directory里面儿,数据集ego-hand不过3G多,不会超过,所以是不用放在scratch space里面的,但是scratch space的设计就是给数据集的IO的,我猜应该把数据放那。然后在Shell中运行代码,调用scratch space的IO。如果说存储空间类型相似或者本身就是同一磁盘分区,我觉得IO读写速度应该不慢。
既然Home directories是很多个用户所使用的,那么scratch space也应该是以用户分的,按照文档,我们进入scratch space看看有什么:
| |
确实如此,而且各自的空间基本都是以文件夹的形式存在。我的目录的长格式为:
| |

| |
咱发现个什么问题呢?我们一般默认进入Home directory,但是Scratch space和Home directory的路径不一样,所以Linux就有一种叫做软链接的符号链接(symlink)让我们通过访问它来访问软链接指向的真正位置。按照文档的方法创建软链接:
| |
scratch这个软链接指向了我的独享的scratch space。这样的一个类似“指针”的操作有什么用呢?比如目标目录/mnt/storage/scratch/lm19073所属用户组emat19t经常对所管理的目录进行更新,把目录都用版本号来区别,而不是我现在的学号,这就很蛋疼了,每次访问目标目录还得去专门看一下版本号,然后敲出来,不如拿一个reference直接建立访问的桥梁。
模块信息
Link。我们可以用module avail来查看所有模块,which <modulename>查看模块位置等,了解了基本信息之后就可以跑代码了。
配置舒服的环境
我重连之后发现上回创建的scratch软链接和本身之前clone的yolov3的repo文件夹都还在home目录下,说明这里的空间都可以保留文件(无备份)。
我们自己的数据怎么上传上去呢?新版文档没有说明,所以我参考了一个较老版本的文档[6],对于使用Windows的我来说,下载winSCP来管理文件流。
现在环境都配置好了!如果有报错,就参考下一章节Issues来解决。一切就绪后,跑代码。
Issues
*Python版本问题
选择运行:
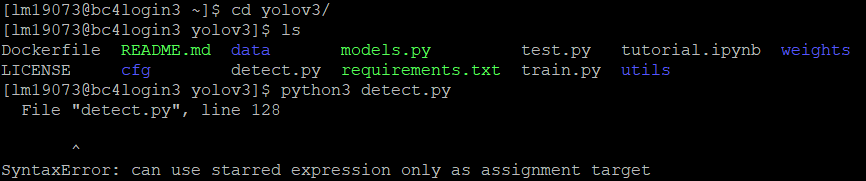
按照issue的说法,BC4的Python 3.4.5版本是导致syntax error的原因,需要≥3.5的版本。采用module avail能发现系统中安装有Anaconda,Anaconda中包含多个不同版本的Python,3.7版本够用,就选择它load到module list中来,之后的python命令就自动调用的是3.7版本的Python了。操作如下:
| |
*libstdc++问题
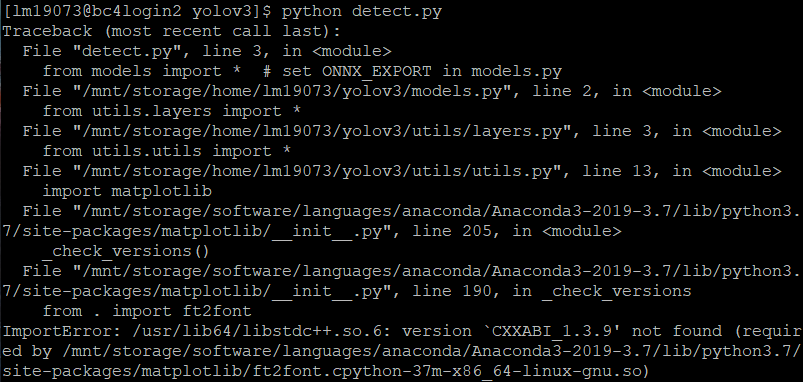
一种可能是libstdc++.so.6没有指向新版本而是6.0.19版本,需要手动解除软链接并创建新软链接,见CXXABI_1.3.9 not included in libstdc++.so.6#5191。
进入libstdc++所在目录
/usr/lib/,检查长格式软链接,1 2 3 4[lm19073@bc4login2 lib64]$ pwd /usr/lib64 [lm19073@bc4login2 lib64]$ ls libstdc++.so.6 -l lrwxrwxrwx 1 root root 19 Mar 21 2017 libstdc++.so.6 -> libstdc++.so.6.0.19需要把这个删掉然后重定义指向下面的地址,不过需要管理员的权限...只要是不乏通过自己的权限解决的办法,不推荐。
1/mnt/storage/software/languages/anaconda/Anaconda3-2019-3.7/lib/libstdc++.so.6.0.26第二种方法是一类方法,就是看是导入什么package的时候出现的error,然后针对性地重装或者更新,见:Link。依然需要管理员权限,不推荐。
第三种方法是最有针对性的,推荐.分析得知这个问题的原因是我们导入的Anaconda的Python模块并没有调用适配的自己的库文件,而是调用了系统的库文件,这两个目录下的
libstdc++有什么区别呢?是版本的区别。1 2 3 4[lm19073@bc4login3 yolov3]$ ls /mnt/storage/software/languages/anaconda/Anaconda3-2019-3.7/lib/libstdc++.so.6 -l lrwxrwxrwx 1 root root 19 Dec 5 2019 /mnt/storage/software/languages/anaconda/Anaconda3-2019-3.7/lib/libstdc++.so.6 -> libstdc++.so.6.0.26 [lm19073@bc4login3 yolov3]$ ls /usr/lib64/libstdc++.so.6 -l lrwxrwxrwx 1 root root 19 Mar 21 2017 /usr/lib64/libstdc++.so.6 -> libstdc++.so.6.0.19解决办法[7]就是让Anaconda调用自己的lib:将Anaconda的lib目录写入动态链接库(DLL)环境变量:
1export LD_LIBRARY_PATH=/mnt/storage/software/languages/anaconda/Anaconda3-2019-3.7/lib:$LD_LIBRARY_PATH
*subprocess.CalledProcessError
报错信息:
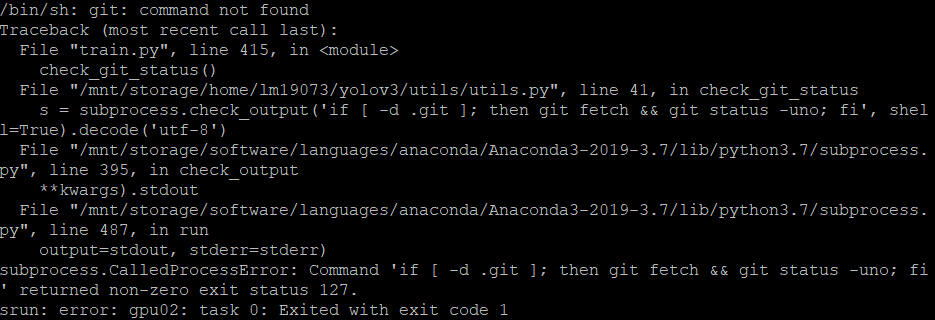
解决:找到git的位置,载入模块列表。
| |
提交作业
BC4的文档对于Job Scheduler讲解基本很清楚,不过对于初学者来说还是比较难懂,文档几乎没有提供可运行脚本的例子,综合多方资源[8][9][10][11],以及在集群上的试错,我总结出两种配置:
SBATCH配置:单GPU
1 2 3 4 5 6 7 8 9 10 11 12 13#!/bin/bash #SBATCH --mail-user=lm19073 #SBATCH --mail-type=BEGIN,END,FAIL #SBATCH --job-name=train-egohand #SBATCH --output=train-egohand_%j.out #SBATCH --error=train-egohand_%j.err #SBATCH --nodes=1 #SBATCH --ntasks-per-node=4 #SBATCH --time=24:00:00 #SBATCH --mem=15G #SBATCH --partition=gpu #SBATCH --gres=gpu:1SBATCH配置:多GPU
1 2 3 4 5 6 7 8 9 10 11 12 13#!/bin/bash #SBATCH --mail-user=lm19073 #SBATCH --mail-type=BEGIN,END,FAIL #SBATCH --job-name=train-epichands #SBATCH --output=train-epichands_%j.out #SBATCH --error=train-epichands_%j.err #SBATCH --nodes=1 #SBATCH --ntasks-per-node=4 #SBATCH --time=3-00:00:00 #SBATCH --mem=16G #SBATCH --partition=gpu #SBATCH --gres=gpu:2
上文说到配置出能跑训练代码的环境,在BC4中,有几个模块是必需的:
| |
接下来就是自己跑py程序的训练的命令语句。可以参考两个脚本示例:
- Single GPU: train_egohand.sh
- Double GPU: train_epichands.sh
监控GPU状态
我们在shell中通过sbatch命令提交用train.sh设计的作业:
| |
系统会打印一串表示作业ID的代码,如3954950,用JobID表示,如果我们想找到作业正在哪个节点上跑(以及状态):
| |
连接上对应节点,查看GPU使用状态。如果想退出连接,输入exit即可[12]。
| |
References
BlueCrystal Phase 4 User Documentation
3 个相见恨晚的 Google Colaboratory 奇技淫巧!
https://github.com/JinhangZhu/project-diary/issues/2#issue-579922097
https://github.com/JinhangZhu/project-diary/issues/8#issue-612799043
可以参考开源工作者撰写的《快乐的Linux命令行》- http://billie66.github.io/TLCL/
不懂shell别说你会linux - jay的文章 - 知乎 https://zhuanlan.zhihu.com/p/104729643
How to copy files to and from the cluster - ACRC: BlueCrystal User Guide - https://www.acrc.bris.ac.uk/acrc/pdf/bc-user-guide.pdf
Submission Script Examples - Yale Center for Research Computing